Why are only a few of my website’s pages being crawled?
If you’ve noticed that only 4-6 pages of your website are being crawled (your home page, sitemaps URLs and robots.txt), most likely this is because our bot couldn’t find outgoing internal links on your Homepage. Below you will find possible reasons for this issue.
There may be no outgoing internal links on your main page, or they may be wrapped in JavaScript. Our bot parses JavaScript content only with the Guru and Business tiers of the SEO Toolkit subscription. Therefore, if you don’t have the Guru or Business level and your homepage contains links to other parts of your site within JavaScript elements, we won’t detect or crawl those pages.
Although JavaScript crawling is only available with the Guru and Business tiers, we can still crawl the HTML of pages containing JavaScript elements. Additionally, our Performance checks can review the parameters of your JavaScript and CSS files, regardless of your subscription tier.
In both cases, there is a way to ensure that our bot will crawl your pages. To do this, you need to change "Pages to crawl" from “website” to “sitemap” or “URLs from file” in your campaign settings:
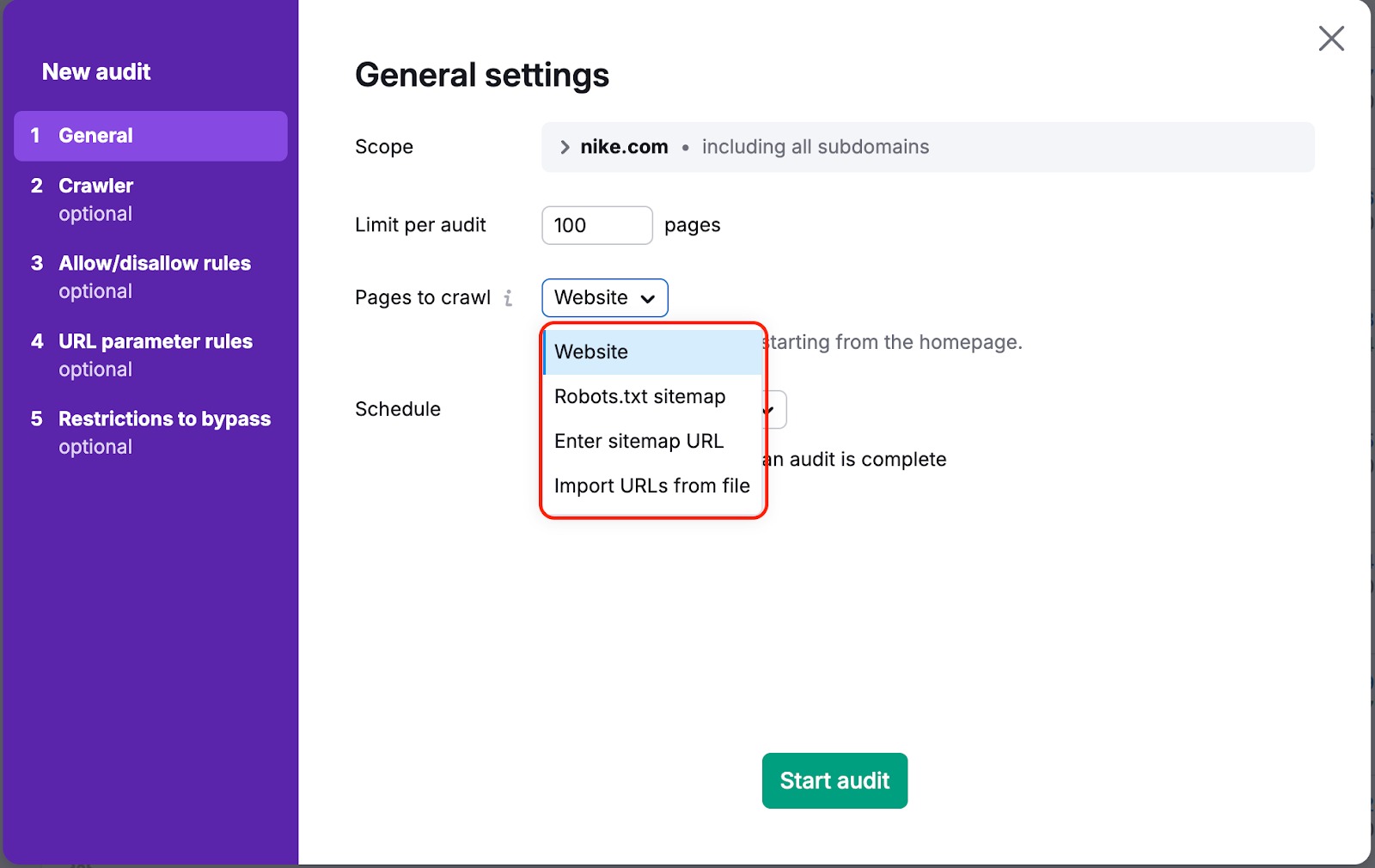
“Website” is a default source. It means we will crawl your website using a breadth-first search algorithm and navigate through the links we see on your page’s code—starting from the homepage.
If you choose one of the other options, we will crawl links that are found in the sitemap or in the file you upload.
Our crawler could have been blocked on some pages in the website’s robots.txt or by noindex/nofollow tags. You can check if this is the case in your Crawled pages report:
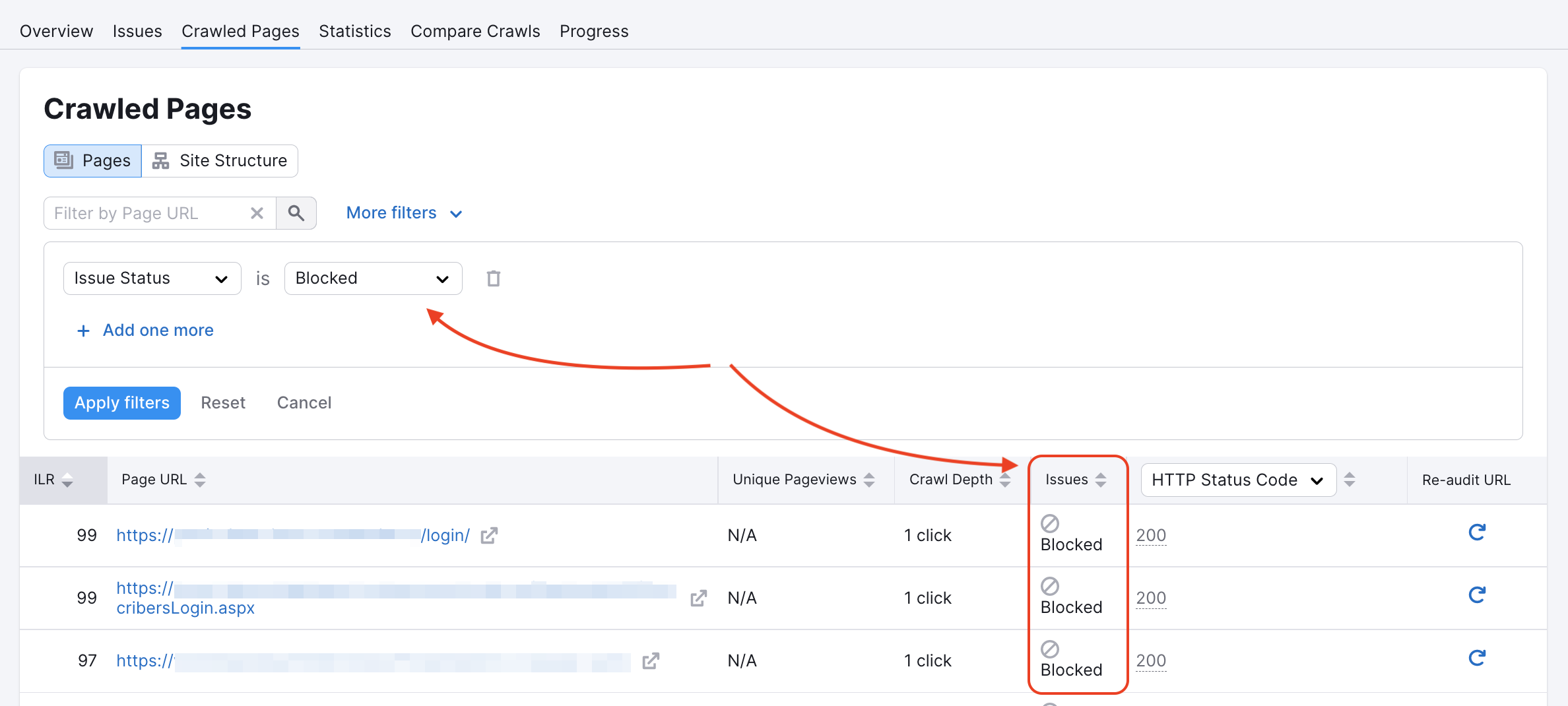
You can inspect your Robots.txt for any disallow commands that would prevent crawlers like ours from accessing your website.
If you see the code shown below on the main page of a website, it tells us that we’re not allowed to index/follow links on it and our access is blocked. Or, a page containing at least one of the two: "nofollow", "none", will lead to a crawling error.
<meta name="robots" content="noindex, nofollow">
You will find more information about these errors in our troubleshooting article.
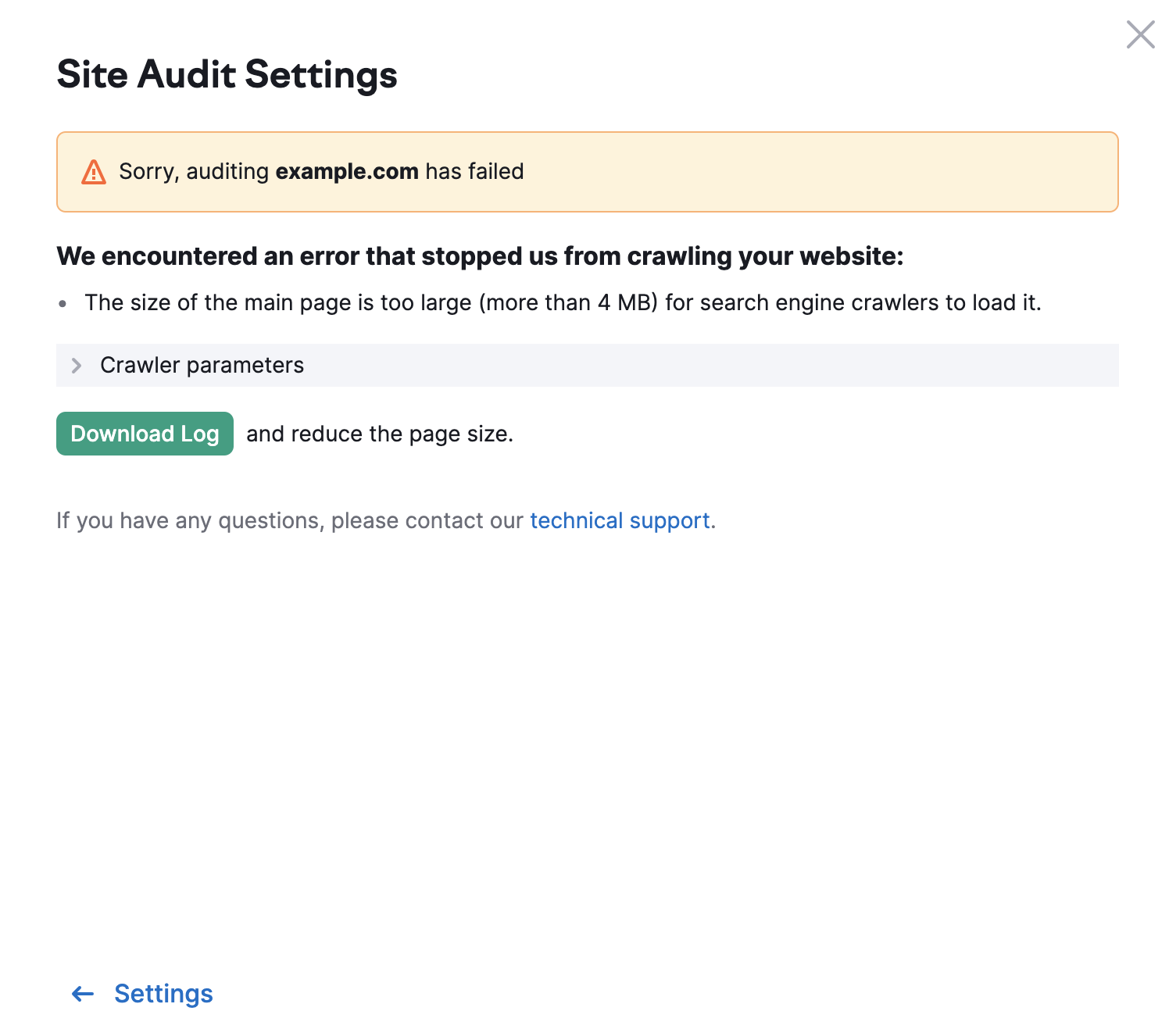
The limit for other pages of your website is 2MB. In case a page has too large HTML size, you will see the following error:
